什么是HTTP? HTTP 和 HTTPS 的区别?
概念
HTTP 是超文本传输协议,默认使用 80 端口,是互联网上应用最为广泛的一种网络协议。是一个客户端和服务器端请求和应答的标准(TCP),用于从 WWW 服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:安全超文本传输协议,默认使用 443 端口。简单讲是 HTTP 的安全版,通过 SSL 加密。
区别
- HTTP 协议的数据传输是明文的,是不安全的,而 HTTPS 使用了 SSL 进行加密传输。
- HTTP 和 HTTPS 的连接方式不同,默认端口也不同,HTTP 是80端口,HTTPS 是443端口。
- HTTPS 由于需要设计加密以及多次握手,性能方面不如 HTTP。
- HTTPS 协议需要到 CA 申请证书,一般免费证书很少,需要交费。
为什么说HTTPS比HTTP安全? HTTPS是如何保证安全的?
因为 HTTPS 使用了 SSL 对内容使用了加密处理,从而保证了传输安全。可以防止数据在传输过程中被监听和被窃取,从而确认网站的真实性。
用了 HTTPS 就一定安全吗?
不一定,因为 HTTPS 保证的只是传输过程的安全。但本地的安全属于另一安全范畴,应对的措施有安装杀毒软件、反木马、浏览器升级修复漏洞等。
如何理解 UDP 和 TCP? 区别? 应用场景?
UDP 是用户数据包协议,是一个简单的「面向数据报的通信协议」,即对应用层交下来的报文,不合并,不拆分,只是在其上面加上首部后就交给了下面的网络层。
TCP 是传输控制协议,是一种可靠的、「面向字节流的通信协议」,把上面应用层交下来的数据看成无结构的字节流来发送。
区别
| TCP | UDP | |
|---|---|---|
| 可靠性 | 可靠 | 不可靠 |
| 连接性 | 面向连接 | 无连接 |
| 报文 | 面向字节流 | 面向报文 |
| 效率 | 传输效率低 | 传输效率高 |
| 双共性 | 全双工 | 一对一、一对多、多对一、多对多 |
| 流量控制 | 滑动窗口 | 无 |
| 拥塞控制 | 慢开始、拥塞避免、快重传、快恢复 | 无 |
| 传输效率 | 慢 | 快 |
TCP 是面向连接的协议,建立连接3次握手、断开连接四次挥手,UDP是面向无连接,数据传输前后不连接连接,发送端只负责将数据发送到网络,接收端从消息队列读取。
TCP 提供可靠的服务,传输过程采用流量控制、编号与确认、计时器等手段确保数据无差错,不丢失。UDP 则尽可能传递数据,但不保证传递交付给对方。
TCP 面向字节流,将应用层报文看成一串无结构的字节流,分解为多个TCP报文段传输后,在目的站重新装配。UDP协议面向报文,不拆分应用层报文,只保留报文边界,一次发送一个报文,接收方去除报文首部后,原封不动将报文交给上层应用。
TCP 只能点对点全双工通信。UDP 支持一对一、一对多、多对一和多对多的交互通信。
应用场景
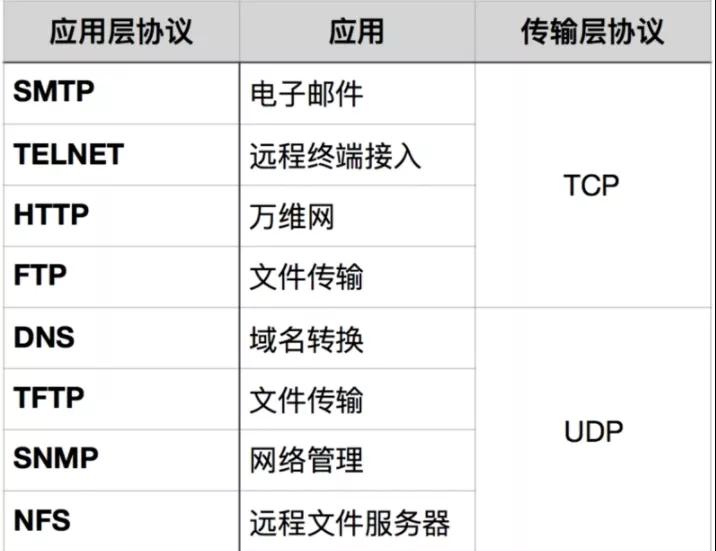
http1.0 1.1 2.0的区别
- HTTP1.0:默认不支持长连接,需要设置keep-alive参数指定,缓存有一定的缺陷。
- HTTP1.1:默认长连接(keep-alive),http请求可以复用Tcp连接,但同一时间只能对应一个http请求,也就是一个Tcp中http请求时串行的,还对缓存进行了优化。
- HTTP2.0:采用二进制格式而非文本格式;能实现多路复用,一个Tcp中多个http请求是并行的;可以将报头数据进行压缩,提高了传输速度;在请求数据时,服务器能主动将一些资源“推送”到客户端中。
状态码
- 100 - 客户端应继续其请求
- 101 - 切换协议
- 200 - 请求成功
- 201 - 请求成功并创建了新的资源
- 202 - 已经接受了请求,但还没有处理完成
- 203 - 非授权信息。
- 204 - 服务器处理成功,但未返回内容。
- 205 - 重置内容(清除表单内容)
- 206 - 部分内容(处理了部分GET请求)
- 301 - 永久重定向(强制get)
- 302 - 临时重定向(强制get)
- 307 - 临时重定向(说了是GET请求的)
- 400 - 请求错误。
- 401 - 请求身份验证。(未授权)
- 403 - 服务器拒绝请求。
- 404 - 服务器没找到资源。
- 408 - 超时
- 500 - 服务器错误
- 501 - 服务器不支持请求
- 502 - 网关错误
- 504 - 网关超时
说一下 GET 和 POST 的区别?
- GET参数通过URL传递(以?分隔,参数之间以&相连),POST放在Request body中。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET请求的数据有大小限制,因为浏览器对url的长度有限制,而POST没有。
- GET请求会被浏览器缓存,而POST需要手动设置。
- GET一般用于查询,POST一般用于提交对信息修改的操作。
- GET在浏览器回退不需要请求,而POST会再次提交请求。
浏览器从输入url到渲染页面,发生了什么?
- 缓存查找
- 浏览器缓存:浏览器会记录DNS一段时间,因此,只是第一个地方解析DNS请求;
- 操作系统缓存:如果在浏览器缓存中不包含这个记录,则会使系统调用操作系统, 获取操作系统的记录(保存最近的DNS查询缓存)
- 路由器缓存:如果上述两个步骤均不能成功获取DNS记录,继续搜索路由器缓存;
- ISP缓存:若上述均失败,继续向ISP搜索
- DNS域名解析
- 建立TCP连接(三次握手)
- 发送HTTP请求,服务器处理请求,返回响应结果
- 浏览器解析渲染页面
- 解析html,构建DOM树
- 解析css,构建CSS树
- 合并DOM树和CSS规则,生成render树
- 布局render树(Layout/reflow),负责各元素尺寸、位置的计算(样式计算)
- 绘制render树(paint),绘制页面像素信息
- 断开连接(四次挥手)
浏览器渲染机制(浏览器绘制过程)
- 将 HTML 解析构建成 DOM 树
- 将 CSS 解析构建成 CSS 树(CSSOM)
- 合并 DOM 树和 CSS 树,生成一棵渲染树 (render)
- 生成布局(Layout),计算出每个节点在屏幕中的位置
- 显示(paint)在屏幕上
重新渲染就是重复之前的第四步(重新生成布局)+第五步(重新绘制)或者只有第五步(重新绘制)。
什么是重绘与重排?有什么区别?
重排(回流): 当 DOM 的变化影响了元素的几何信息 (DOM 对象的位置和尺寸大小),导致浏览器需要重新计算时,这个过程叫做重排。表现为重新生成布局,重新排列元素。
重绘:当一个元素的外观发生改变,但没有改变布局,重新把元素外观绘制出来的过程,叫做重绘。表现为某些元素的外观被改变。
触发:改变元素的color、background、box-shadow等属性
『重排』必定会发生『重绘』,『重绘』不一定会引发『重排』。重排成本高于重绘。
改变父节点中的子节点也可能导致父节点发生重排。
如何触发重排和重绘?
任何改变用来构建渲染树的信息都会导致一次重排或重绘:
- 添加、删除、更新DOM节点
- 通过 display: none 隐藏一个DOM节点-触发重排和重绘
- 通过 visibility: hidden 隐藏一个DOM节点-只触发重绘,因为没有几何变化
- 移动或者给页面中的DOM节点添加动画
- 调整样式属性(元素尺寸改变——边距、填充、边框、宽度和高度 )
- 用户行为,例如调整窗口大小(resize事件),改变字号,或者滚动。
- 内容变化,比如用户在 input 框中输入文字
- 计算 offsetWidth 和 offsetHeight 属性
如何避免重绘或者重排?
- 集中改变样式,不要一条一条地修改 DOM 的样式。
- 不要把 DOM 结点的属性值放在循环里当成循环里的变量。
- 为动画的 HTML 元件使用 fixed 或 absoult 的 position,那么修改他们的 CSS 是不会 reflow 的。
- 不使用 table 布局。因为可能很小的一个小改动会造成整个 table 的重新布局。
- 把 DOM 离线后修改。如:使用 documentFragment 对象在内存里操作 DOM
- 尽量只修改position:absolute或fixed元素,对其他元素影响不大
- 动画开始GPU加速,translate使用3D变化。transform 不重绘、不回流,是因为transform属于合成属性,对合成属性进行transition/animate动画时,将会创建一个合成层。这使得动画元素在一个独立的层中进行渲染。当元素的内容没有发生改变,就没有必要进行重绘。浏览器会通过重新复合来创建动画帧。
- 提升为合成层
将元素提升为合成层有以下优点:- 合成层的位图,会交由 GPU 合成,比 CPU 处理要快
- 当需要 repaint 时,只需要 repaint 本身,不会影响到其他的层
- 对于 transform 和 opacity 效果,不会触发 layout 和 paint
提升合成层的最好方式是使用 CSS 的 will-change 属性:
#target {
will-change: transform;
}
浏览器乱码的原因是什么?如何解决?
产生乱码的原因:网页中的编码和我们编写代码文字使用的编码不同,或者和数据库导出的文字编码不同;还有就是浏览器检测不到网页的编码,也会出现乱码的情况。
- 网页是gbk,而代码中的文字是utf-8,反之也会出现乱码;
- 网页编码是gbk,而数据库导出的文字是utf-8,这样也会造成乱码;
- 浏览器不能自动检测网页编码,造成网页乱码。
解决办法:如果是编写问题,则在编辑HTML网页时自己设置编码格式;如果是数据库编码问题,则在查询数据库时设置相应的编码格式;如果是浏览器自身问题,则在转换编码的菜单中进行转换。
- 编辑HTML网页时自己设置编码格式;
- 如果网页编码是gbk,而数据库数据编码是UTF-8,则查询数据库数据时对程序转码;
- 如果浏览器浏览时候出现网页乱码,在浏览器中找到转换编码的菜单进行转换。
html 规范中为什么要求引用资源不加协议头http或者https?
如果使用 http 或 https 协议来浏览,那么网页中的资源也只能通过相应协议来引用,否则就会出现警告信息,而且不同浏览器的警告信息展现形式不同。为了解决这个问题,我们可以省略 URL 的协议声明,无论是使用哪一个协议访问页面,浏览器都会以相同的协议请求页面中的资源,避免弹出警告信息,同时还可以节省5字节的数据量。
为什么css放在顶部而js写在后面
- 浏览器预先加载css后,可以不必等待HTML加载完毕就可以渲染页面了。
- HTML渲染是一边解析DOM一边渲染,并不会等到完全加载完才渲染页面。
- js写在尾部,主要是:一方面是js主要对事件进行处理,很多操作都是在页面渲染后才执行的。另一方面能节省加载时间,提高用户的体验。
但是随着JS技术的发展,JS也开始承担页面渲染的工作。比如我们的UI其实可以分被对待,把渲染页面的js放在前面,时间处理的js放在后面
常见的浏览器端的存储技术有哪些?
浏览器常见的存储技术有 cookie、localStorage 和 sessionStorage。
还有两种存储技术用于大规模数据存储,webSQL(已被废除)和 indexDB。
IE 支持 userData 存储数据,但是基本很少使用到,除非有很强的浏览器兼容需求。
请描述一下 cookies,sessionStorage 和 localStorage 的区别?
- 它们都存储在客户端,但 cookie 的数据会自动传递到服务器。(同源的http请求中携带)
- 大小限制不同;cookie 数据大小不能超过4k;sessionStorage 和 localStorage 的存储比 cookie 大得多,可以达到5M。
- 数据有效期不同;cookie 在过期时间之前一直有效,即使窗口和浏览器关闭;sessionStorage数据只在当前浏览器窗口有效,关闭了就会被销毁;而 localStorage 永久存储,即使关闭浏览器,也不会消失,除非主动删除数据。
token、cookie、session三者的理解
1、token就是令牌,比如你授权(登录)一个程序时,他就是个依据,判断你是否已经授权该软件(最好的身份认证,安全性好,且是唯一的)
用户身份的验证方式
2、cookie是写在客户端一个txt文件,里面包括登录信息之类的,这样你下次在登录某个网站,就会自动调用cookie自动登录用户名
服务器生成,发送到浏览器,浏览器会保存,下次请求再次发送给服务器(存放着登录信息)
3、session是一类用来客户端和服务器之间保存状态的解决方案,会话完成被销毁。cookie中存放着sessionID,请求会发送这个id。sesion因为request对象而产生。
服务器和客户端的一次会话过程
cookie与session区别
- cookie 数据存放在客户端上,session 数据放在服务器上。
- cookie 不是很安全,别人可以分析存放在本地的 COOKIE 并进行 COOKIE 欺骗,考虑到安全应当使用 session。
- session 会在一定时间内保存在服务器上。当访问增多,会比较占用服务器的性能,考虑到减轻服务器性能方面,应当使用 COOKIE。
- 单个 cookie 保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个 cookie。
session与token区别
- session 只是存储了一些简单的用户信息,且 sessionID 是不可预测的,一种认证手段。只存在服务端,不能与其他的网站或App共享
- token 提供认证和授权,认证针对用户,授权针对App,目的是让某APP有权访问某用户的信息。Token是唯一的,token不能转移到其他的App,也不能转到其他用户上。(适用于App)
- session的状态是存在服务器端的,客户端只存在session id, Token状态是存储在客户端的
TCP 三次握手
- 客户端发送 syn 包到服务器,等待服务器确认接收。
- 服务器确认接收 syn 包并确认客户的 syn,并发送一个 syn+ack 的包给客户端。
- 客户端确认接收服务器的 syn+ack 包,并向服务器发送确认包 ack,二者相互建立联系后,完成 tcp 三次握手。
TCP 四次挥手
- 客户端发送一个 FIN 报文并指定一个序列号到服务器,等待服务端的确认,然后进入 FIN_WAIT1 状态。
- 服务端收到 FIN 报文后,会发送一个 ACK 报文给客户端,表明已经收到客户端的报文了,然后进入 CLOSE_WAIT 状态
- 服务端发送一个 FIN 报文并指定一个序列号,等待客户端的确认,然后进入 LAST_ACK 状态。
- 客户端收到 FIN 报文后,会发送一个 ACK 报文给服务端,然后进入 TIME_WAIT 状态。过一阵子后进入 CLOSED 状态,服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态

